| |
| Version | 34 |
| Editors | Steven Loomis (srl@icu-project.org) and other CLDR committee members |
For the full header, summary, and status, see Part 1: Core
This document describes parts of an XML format (vocabulary) for the exchange of structured locale data. This format is used in the Unicode Common Locale Data Repository.
This is a partial document, describing keyboard mappings. For the other parts of the LDML see the main LDML document and the links above.
This document has been reviewed by Unicode members and other interested parties, and has been approved for publication by the Unicode Consortium. This is a stable document and may be used as reference material or cited as a normative reference by other specifications.
A Unicode Technical Standard (UTS) is an independent specification. Conformance to the Unicode Standard does not imply conformance to any UTS.
Please submit corrigenda and other comments with the CLDR bug reporting form [Bugs]. Related information that is useful in understanding this document is found in the References. For the latest version of the Unicode Standard see [Unicode]. For a list of current Unicode Technical Reports see [Reports]. For more information about versions of the Unicode Standard, see [Versions].
The LDML specification is divided into the following parts:
The CLDR keyboard format provides for the communication of keyboard mapping data between different modules, and the comparison of data across different vendors and platforms. The standardized identifier for keyboards can be used to communicate, internally or externally, a request for a particular keyboard mapping that is to be used to transform either text or keystrokes. The corresponding data can then be used to perform the requested actions.
For example, a web-based virtual keyboard may transform text in the following way. Suppose the user types a key that produces a "W" on a qwerty keyboard. A web-based tool using an azerty virtual keyboard can map that text ("W") to the text that would have resulted from typing a key on an azerty keyboard, by transforming "W" to "Z". Such transforms are in fact performed in existing web applications.
The data can also be used in analysis of the capabilities of different keyboards. It also allows better interoperability by making it easier for keyboard designers to see which characters are generally supported on keyboards for given languages.
To illustrate this specification, here is an abridged layout representing the English US 101 keyboard on the Mac OSX operating system (with an inserted long-press example). For more complete examples, and information collected about keyboards, see keyboard data in XML.
<keyboard locale="en-t-k0-osx">
<version platform="10.4" number="$Revision: 8294 $" />
<names>
<name value="U.S." />
</names>
<keyMap>
<map iso="E00" to="`" />
<map iso="E01" to="1" />
<map iso="D01" to="q" />
<map iso="D02" to="w" />
<map iso="D03" to="e" longPress="é è ê ë" />
…
</keyMap>
<keyMap modifiers="caps">
<map iso="E00" to="`" />
<map iso="E01" to="1" />
<map iso="D01" to="Q" />
<map iso="D02" to="W" />
…
</keyMap>
<keyMap modifiers="opt">
<map iso="E00" to="`" />
<map iso="E01" to="¡" /> <!-- key=1 -->
<map iso="D01" to="œ" /> <!-- key=Q -->
<map iso="D02" to="∑" /> <!-- key=W -->
…
</keyMap>
<transforms type="simple">
<transform from="` " to="`" />
<transform from="`a" to="à" />
<transform from="`A" to="À" />
<transform from="´ " to="´" />
<transform from="´a" to="á" />
<transform from="´A" to="Á" />
<transform from="˜ " to="˜" />
<transform from="˜a" to="ã" />
<transform from="˜A" to="Ã" />
…
</transforms>
</keyboard>
And its associated platform file (which includes the hardware mapping):
<platform id="osx">
<hardwareMap>
<map keycode="0" iso="C01" />
<map keycode="1" iso="C02" />
<map keycode="6" iso="B01" />
<map keycode="7" iso="B02" />
<map keycode="12" iso="D01" />
<map keycode="13" iso="D02" />
<map keycode="18" iso="E01" />
<map keycode="50" iso="E00" />
</hardwareMap>
</platform>
Some goals of this format are:
Some non-goals (outside the scope of the format) currently are:
Note: During development of this section, it was considered whether the modifier RAlt (=AltGr) should be merged with Option. In the end, they were kept separate, but for comparison across platforms implementers may choose to unify them.
Note that in parts of this document, the format @x is used to indicate the attribute x.
Arrangement is the term used to describe the relative position of the rectangles that represent keys, either physically or virtually. A physical keyboard has a static arrangement while a virtual keyboard may have a dynamic arrangement that changes per language and/or layer. While the arrangement of keys on a keyboard may be fixed, the mapping of those keys may vary.
Base character: The character emitted by a particular key when no modifiers are active. In ISO terms, this is group 1, level 1.
Base map: A mapping from the ISO positions to the base characters. There is only one base map per layout. The characters on this map can be output by not using any modifier keys.
Core keyboard layout: also known as “alpha” block. The primary set of key values on a keyboard that are used for typing the target language of the keyboard. For example, the three rows of letters on a standard US QWERTY keyboard (QWERTYUIOP, ASDFGHJKL, ZXCVBNM) together with the most significant punctuation keys. Usually this equates to the minimal keyset for a language as seen on mobile phone keyboards.
Hardware map: A mapping between key codes and ISO layout positions.
Input Method Editor (IME): a component or program that supports input of large character sets. Typically, IMEs employ contextual logic and candidate UI to identify the Unicode characters intended by the user.
ISO position: The corresponding position of a key using the
ISO layout convention where rows are identified by letters and
columns are identified by numbers. For example, "D01" corresponds to
the "Q" key on a US keyboard. For the purposes of this document, an
ISO layout position is depicted by a one-letter row identifier
followed by a two digit column number (like "B03", "E12" or "C00").
The following diagram depicts a typical US keyboard layout
superimposed with the ISO layout indicators (it is important to note
that the number of keys and their physical placement relative to
each-other in this diagram is irrelevant, rather what is important is
their logical placement using the ISO convention):
One may also extend the notion of the ISO layout to support keys that don't map directly to the diagram above (such as the Android device - see diagram). Per the ISO standard, the space bar is mapped to "A03", so the period and comma keys are mapped to "A02" and "A04" respectively based on their relative position to the space bar. Also note that the "E" row does not exist on the Android keyboard.
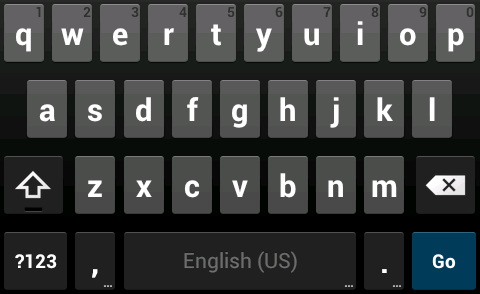
If it becomes necessary in the future, the format could extend the ISO layout to support keys that are located to the left of the "00" column by using negative column numbers "-01", "-02" and so on, or 100's complement "99", "98",...
Key: A key on a physical keyboard.
Key code: The integer code sent to the application on pressing a key.
Key map: The basic mapping between ISO positions and the output characters for each set of modifier combinations associated with a particular layout. There may be multiple key maps for each layout.
Keyboard: The physical keyboard.
Keyboard layout: A layout is the overall keyboard configuration for a particular locale. Within a keyboard layout, there is a single base map, one or more key maps and zero or more transforms.
Layer is an arrangement of keys on a virtual keyboard. Since it is often not intended to use two hands on a visual keyboard to allow the pressing of modifier keys. Modifier keys are made sticky in that one presses one, the visual representation, and even arrangement, of the keys change, and you press the key. This visual representation is a layer. Thus a virtual keyboard is made up of a set of layers.
Long-press key: also known as a “child key”. A secondary key that is invoked from a top level key on a software keyboard. Secondary keys typically provide access to variants of the top level key, such as accented variants (a => á, à, ä, ã)
Modifier: A key that is held to change the behavior of a keyboard. For example, the "Shift" key allows access to upper-case characters on a US keyboard. Other modifier keys include but is not limited to: Ctrl, Alt, Option, Command and Caps Lock.
Physical keyboard is a keyboard that has individual keys that are pressed. Each key has a unique identifier and the arrangement doesn't change, even if the mapping of those keys does.
Transform:A transform is an element that specifies a set of conversions from sequences of code points into one (or more) other code points. For example, in most latin keyboards hitting the "^" dead-key followed by the "e" key produces "ê".
Virtual keyboard is a keyboard that is rendered on a, typically, touch surface. It has a dynamic arrangement and contrasts with a physical keyboard. This term has many synonyms: touch keyboard, software keyboard, SIP (Software Input Panel). This contrasts with other uses of the term virtual keyboard as an on-screen keyboard for reference or accessibility data entry.
Each platform has its own directory, where a "platform" is a designation for a set of keyboards available from a particular source, such as Windows or Chromeos. This directory name is the platform name (see Table 2 located further in the document). Within this directory there are two types of files:
Keyboard data that is not supported on a given platform, but intended for use with that platform, may be added to the directory /und/. For example, there could be a file /und/lt-t-k0-chromeos.xml, where the data is intended for use with ChromeOS, but does not reflect data that is distributed as part of a standard ChromeOS release.
This is the top level element. All other elements defined below are under this element.
Syntax
<keyboard locale="{locale ID}">
{definition of the layout as described by the elements defined below}
</keyboard>
Examples (for illustrative purposes only, not indicative of the real data)
<keyboard locale="ka-t-k0-qwerty-windows"> … </keyboard> <keyboard locale="fr-CH-t-k0-android"> … </keyboard>
Element used to keep track of the source data version.
Syntax
<version platform=".." revision="..">
Example
<keyboard locale="..-osx">
…
<version platform="10.4" number="1"/>
…
</keyboard>
The generation element is now deprecated. It was used to keep track of the generation date of the data.
Element used to store any names given to the layout by the platform.
Syntax
<names>
{set of name elements}
</names>
A single name given to the layout by the platform.
Syntax
<name value="..">
Example
<keyboard locale="bg-t-k0-windows-phonetic-trad">
…
<names>
<name value="Bulgarian (Phonetic Traditional)"/>
</names>
…
</keyboard>
An element used to keep track of layout specific settings. This
element may or may not show up on a layout. These settings reflect
the normal practice on the platform. However, an implementation using
the data may customize the behavior. For example, for
transformFailures the implementation could ignore the setting, or
modify the text buffer in some other way (such as by emitting
backspaces).
Syntax
<settings [fallback="omit"]
[transformFailure="omit"]
[transformPartial="hide"]>
If this attribute is present, it must have a value of omit.
^e → ê
^a → â
Suppose a user now enters the "^" key then "^" is now stored in a buffer and may or may not be shown to the user (see the partial attribute).
If a user now enters d, then the transform has failed and there are two options for output.
1. default behavior - "^d"
2. omit - "" (nothing and the buffer is cleared)
The default behavior (when this attribute is not present) is to emit the contents of the buffer upon failure of a transform.
If this attribute is present, it must have a value of omit.
By default (when this attribute is not present), show the values of the buffer as the user is typing a transform (this behavior can be seen on the Mac OSX platform).
If this attribute is present, it must have a value of hide.
Example
<keyboard locale="bg-t-k0-windows-phonetic-trad">
…
<settings fallback="omit" transformPartial="hide">
…
</keyboard>
Indicates that:
This element defines the group of mappings for all the keys that use the same set of modifier keys. It contains one or more map elements.
Syntax
<keyMap [modifiers="{Set of Modifier Combinations}"]>
{a set of map elements}
</keyMap>
A modifier key may be further specified to be in a "don't care" state using the '?' suffix. The "don't care" state simply means that the preceding modifier key may be either ON or OFF. For example "ctrl+shift?" could be expanded into "ctrl ctrl+shift".
Within a combination, the presence of a modifier WITHOUT the '?' suffix indicates this key MUST be on. The converse is also true, the absence of a modifier key means it MUST be off for the combination to be active.
Here is an exhaustive list of all possible modifier keys:
Possible Modifier Keys
Modifier Keys |
Comments |
|
altL |
altR |
xAlty → xAltR+AltL? xAltR?AltLy |
ctrlL |
ctrlR |
ditto for Ctrl |
shiftL |
shiftR |
ditto for Shift |
optL |
optR |
ditto for Opt |
caps |
Caps Lock |
|
cmd |
Command on the Mac |
All sets of modifier combinations within a layout are disjoint with no-overlap existing between the key maps. That is, for every possible modifier combination, there is at most a single match within the layout file. There are thus never multiple matches. If no exact match is available, the match falls back to the base map unless the fallback="omit" attribute in the settings element is set, in which case there would be no output at all.
To illustrate, the following example produces an invalid layout because pressing the "Ctrl" modifier key produces an indeterminate result:
<keyMap modifiers="ctrl+shift?">
…
</keyMap>
<keyMap modifiers="ctrl">
…
</keyMap>
Modifier Examples:
<keyMap modifiers="cmd?+opt+caps?+shift" />
Caps-Lock may be ON or OFF, Option must be ON, Shift must be ON and Command may be ON or OFF.
<keyMap modifiers="shift caps" fallback="true" />
Caps-Lock must be ON OR Shift must be ON. Is also the fallback key map.
If the modifiers attribute is not present on a keyMap then that particular key map is the base map.
This element defines a mapping between the base character and the output for a particular set of active modifier keys. This element must have the keyMap element as its parent.
If a map element for a particular ISO layout position has not been defined then if this key is pressed, no output is produced.
Syntax
<map
iso="{the iso position}"
to="{the output}"
[longPress="{long press keys}"]
[transform="no"]
/><!-- {Comment to improve readability (if needed)} -->

For example, suppose there are the following keys, their output and one transform:
E00 outputs `
Option+E00 outputs ` (the dead-version which participates in transforms).
`e → è
Then the first key must be tagged with transform="no" to indicate that it should never participate in a transform.
Comment: US key equivalent, base key, escaped output and escaped longpress
In the generated files, a comment is included to help the readability of the document. This comment simply shows the English key equivalent (with prefix key=), the base character (base=), the escaped output (to=) and escaped long-press keys (long=). These comments have been inserted strategically in places to improve readability. Not all comments include include all components since some of them may be obvious.
Examples
<keyboard locale="fr-BE-t-k0-windows">
…
<keyMap modifiers="shift">
<map iso="D01" to="A" /> <!-- key=Q -->
<map iso="D02" to="Z" /> <!-- key=W -->
<map iso="D03" to="E" />
<map iso="D04" to="R" />
<map iso="D05" to="T" />
<map iso="D06" to="Y" />
…
</keyMap>
…
</keyboard>
<keyboard locale="ps-t-k0-windows">
…
<keyMap modifiers='altR+caps? ctrl+alt+caps?'>
<map iso="D04" to="\u{200e}" /> <!-- key=R base=ق -->
<map iso="D05" to="\u{200f}" /> <!-- key=T base=ف -->
<map iso="D08" to="\u{670}" /> <!-- key=I base=ه to= ٰ -->
…
</keyMap>
…
</keyboard>
<!ELEMENT keyMap ( map | flicks )+ >
<!ELEMENT flick EMPTY>
<!ATTLIST flick directions NMTOKENS>
<!ATTLIST flick to CDATA>
<!--@VALUE-->
The flicks element is used to generate results from a "flick" of the finger on a mobile device. The directions attribute value is a space-delimited list of keywords, that describe a path, currently restricted to the cardinal and intercardinal directions {n e s w ne nw se sw}. The to attribute value is the result of (one or more) flicks.
Example: where a flick to the Northeast then South produces two code points.
<flicks iso="C01"> <flick directions=“ne s” to=“\uABCD\uDCBA”> </flicks>
The import element references another file of the same type and includes all the subelements of the top level element as though the import element were being replaced by those elements, in the appropriate section of the XML file. For example:
<import path="standard_transforms.xml">
If two identical elements, as described below, are defined, the later element will take precedence. Thus if a hardwareMap/map for the same keycode on the same page is defined twice (for example once in an included file), the later one will be the resulting mapping.
Elements are considered to have three attributes that make them unique: the tag of the element, the parent and the identifying attribute. The parent in its turn is a unique element and so on up the chain. If the distinguishing attribute is optional, its non-existence is represented with an empty value. Here is a list of elements and their defining attributes. If an element is not listed then if it is a leaf element, only one occurs and it is merely replaced. If it has children, then the sub elements are considered, in effect merging the element in question.
Element |
Parent |
Distinguishing attribute |
keyMap |
keyboard |
@modifiers |
map |
keyMap |
@iso |
display |
displayMap |
@char (new) |
layout |
layouts |
@modifier |
In order to help identify mistakes, it is an error if a file contains two elements that override each other. All element overrides must come as a result of an <include> element either for the element overridden or the element overriding.
The following elements are not imported from the source file:
The displayMap can be used to describe what is to be displayed on the keytops for various keys. For the most part, such explicit information is unnecessary since the @char element from the keyMap/map element can be used. But there are some characters, such as diacritics, that do not display well on their own and so explicit overrides for such characters can help. The displayMap consists of a list of display sub elements.
DisplayMaps are designed to be shared across many different keyboard layout descriptions, and included in where needed.
The display element describes how a character, that has come from a keyMap/map element, should be displayed on a keyboard layout where such display is possible.
<keyboard > <keyboardMap> <map iso="C01" to="a" longpress="\u0301 \u0300"/> </keyboardMap> <displayMap> <display mapOutput="\u0300" display="u\u02CB"/> <display mapOutput="\u0301" display="u\u02CA"/> </displayMap>
</keyboard >
To allow displayMaps to be shared across descriptions, there is no requirement that @mapOutput matches any @to in any keyMap/map element in the keyboard description.
A layer element describes the configuration of keys on a particular layer of a keyboard. It contains row elements to describe which keys exist in each row and also switch elements that describe how keys in the layer switch the layer to another. In addition, for platforms that require a mapping from a key to a virtual key (for example Windows or Mac) there is also a vkeys element to describe the mapping.
The keymap/@modifier often includes multiple combinations that match. It is not necessary (or prefered) to include all of these. Instead a minimal matching element should be used, such that exactly one keymap is matched.
The following are examples of situations where the @modifiers and @modifier do not match, with a different keymap definition than above.
keyMap/@modifiers |
layer/@modifier |
|---|---|
shiftL |
shift (ambiguous) |
altR |
alt |
shiftL?+shiftR |
shift |
And these do match:
keyMap/@modifiers |
layer/@modifier |
|---|---|
shiftL shiftR |
shift |
The use of @modifier as an identifier for a layer, is sufficient since it is always unique among the set of layer elements in a keyboard.
A row element describes the keys that are present in the row of a keyboard. Row elements are ordered within a layout element with the top visual row being stored first. The row element introduces the keyId which may be an ISOKey or a specialKey. More formally:
keyId = ISOKey | specialKey
ISOKey = [A-Z][0-9][0-9]
specialKey = [a-z][a-zA-Z0-9]{2,7}
ISOKey denotes a key having an ISO Position. SpecialKey is used to identify functional keys occurring on a virtual keyboard layout.
specialKey type keyIds may take any value within their syntactic constraint. But the following specialKeys are reserved to allow applications to identify them and give them special handling:
Here is an example of a row element:
<layer modifier="none"> <row keys="D01-D10"/> <row keys="C01-C09"/> <row keys="shift B01-B07 bksp"/> <row keys="sym A01 smilies A02-A03 enter"/> </layer>
The switch element describes a function key that has been included in the layout. It specifies which layer pressing the key switches you to and also what the key looks like.
Here is an example of a switch element for a shift key:
<layer modifier="none"> <row keys="D01-D10"/> <row keys="C01-C09"/> <row keys="shift B01-B07 bksp"/> <row keys="sym A01 smilies A02-A03 enter"/> <switch iso="shift" layout="shift" display="⇪"/> </layer> <layer modifier="shift"> <row keys="D01-D10"/> <row keys="C01-C09"/> <row keys="shift B01-B07 bksp"/> <row keys="sym A01 smilies A02-A03 enter"/> <switch iso="shift" layout="none" display="⇪"/> </layer>
On some architectures, applications may directly interact with keys before they are converted to characters. The keys are identified using a virtual key identifier or vkey. The mapping between a physical keyboard key and a vkey is keyboard-layout dependent. For example, a French keyboard would identify the D01 key as being an 'a' with a vkey of 'a' as opposed to 'q' on a US English keyboard. While vkeys are layout dependent, they are not modifier dependent. A shifted key always has the same vkey as its unshifted counterpart. In effect, a key is identified by its vkey and the modifiers active at the time the key was pressed.
For a physical keyboard there is a layout specific default mapping of keys to vkeys. These are listed in a vkeys element which takes a list of vkey element mappings and is identified by a type. There are different vkey mappings required for different platforms. While type="windows" vkeys are very similar to type="osx" vkeys, they are not identical and require their own mapping.
The most common model for specifying vkeys is to import a standard mapping, say to the US layout, and then to add a vkeys element to change the mapping appropriately for the specific layout.
In addition to describing physical keyboards, vkeys also get used in virtual keyboards. Here the vkey mapping is local to a layer and therefore a vkeys element may occur within a layout element. In the case where a layout element has no vkeys element then the resulting mapping may either be empty (none of the keys represent keys that have vkey identifiers) or may fallback to the layout wide vkeys mapping. Fallback only occurs if the layout's modifier attribute consists only of standard modifiers as listed as being reserved in the description of the layout/@modifier attribute, and if the modifiers are standard for the platform involved. So for Windows, 'cmd' is a reserved modifier but it is not standard for Windows. Therefore on Windows the vkey mapping for a layout with @modifier="cmd" would be empty.
A vkeys element consists of a list of vkey elements.
A vkey element describes a mapping between a key and a vkey for a particular platform.
This example shows some of the mappings for a French keyboard layout:
shared/win-vkey.xml <keyboard> <vkeys type="windows"> <vkey iso="D01" vkey="VK_Q"/> <vkey iso="D02" vkey="VK_W"/> <vkey iso="C01" vkey="VK_A"/> <vkey iso="B01" vkey="VK_Z"/> </vkeys> </keyboard>
shared/win-fr.xml <keyboard> <import path="shared/win-vkey.xml"> <keyMap> <map iso="D01" to="a"/> <map iso="D02" to="z"/> <map iso="C01" to="q"/> <map iso="B01" to="w"/> </keyMap>
<keyMap modifiers="shift"> <map iso="D01" to="A"/> <map iso="D02" to="Z"/> <map iso="C01" to="Q"/> <map iso="B01" to="W"/> </keyMap>
<vkeys type="windows"> <vkey iso="D01" vkey="VK_A"/> <vkey iso="D02" vkey="VK_Z"/> <vkey iso="C01" vkey="VK_Q"/> <vkey iso="B01" vkey="VK_W"/> </vkeys> </keyboard>
In the context of a virtual keyboard there might be a symbol layer with the following layout:
<keyboard>
<keyMap>
<map iso="D01" to="1"/>
<map iso="D02" to="2"/>
...
<map iso="D09" to="9"/>
<map iso="D10" to="0"/>
<map iso="C01" to="!"/>
<map iso="C02" to="@"/>
...
<map iso="C09" to="("/>
<map iso="C10" to=")"/>
</keyMap>
<layer modifier="sym">
<row keys="D01-D10"/>
<row keys="C01-C09"/>
<row keys="shift B01-B07 bksp"/>
<row keys="sym A00-A03 enter"/>
<switch iso="sym" layout="none" display="ABC"/>
<switch iso="shift" layout="sym+shift" display="&=/<"/>
<vkeys type="windows">
<vkey iso="D01" vkey="VK_1"/>
...
<vkey iso="D10" vkey="VK_0"/>
<vkey iso="C01" vkey="VK_1" modifier="shift"/>
...
<vkey iso="C10" vkey="VK_0" modifier="shift"/>
</vkeys>
</layer>
</keyboard>
This element defines a group of one or more transform elements associated with this keyboard layout. This is used to support such as dead-keys using a straightforward structure that works for all the keyboards tested, and that results in readable source data.
There can be multiple <transforms> elements
Syntax
<transforms type="...">
{a set of transform elements}
</transforms>
This element must have the transforms element as its parent. This element represents a single transform that may be performed using the keyboard layout. A transform is an element that specifies a set of conversions from sequences of code points into one (or more) other code points.. For example, in most French keyboards hitting the "^" dead-key followed by the "e" key produces "ê".
Syntax
<transform from="{combination of characters}" to="{output}">
For example, suppose there are the following transforms:
^e → ê
^a → â
^o → ô
If the user types a key that produces "^", the keyboard enters a dead state. When the user then types a key that produces an "e", the transform is invoked, and "ê" is output. Suppose a user presses keys producing "^" then "u". In this case, there is no match for the "^u", and the "^" is output if the failure attribute in the transform element is set to emit. If there is no transform starting with "u", then it is also output (again only if failure is set to emit) and the mechanism leaves the "dead" state.
The UI may show an initial sequence of matching characters with a special format, as is done with dead-keys on the Mac, and modify them as the transform completes. This behavior is specified in the partial attribute in the transform element.
Most transforms in practice have only a couple of characters. But for completeness, the behavior is defined on all strings:
Suppose that there is the following transforms:
ab → x
abc → y
abef → z
bc → m
beq → n
Here's what happens when the user types various sequence characters:
Input characters |
Result |
Comments |
ab |
No output, since there is a longer transform with this as prefix. |
|
abc |
y |
Complete transform match. |
abd |
xd |
The longest match is "ab", so that is converted and output. The 'd' follows, since it is not the start of any transform. |
abeq |
xeq |
"ab" wins over "beq", since it comes first. That is, there is no longer possible match starting with 'a'. |
bc |
m |
Control characters, combining marks and whitespace in this attribute are escaped using the \u{...} notation.
Control characters, whitespace (other than the regular space character) and combining marks in this attribute are escaped using the \u{...} notation.
Examples
<keyboard locale="fr-CA-t-k0-CSA-osx">
<transforms type="simple">
<transform from="´a" to="á" />
<transform from="´A" to="Á" />
<transform from="´e" to="é" />
<transform from="´E" to="É" />
<transform from="´i" to="í" />
<transform from="´I" to="Í" />
<transform from="´o" to="ó" />
<transform from="´O" to="Ó" />
<transform from="´u" to="ú" />
<transform from="´U" to="Ú" />
</transforms>
...
</keyboard>
<keyboard locale="nl-BE-t-k0-chromeos">
<transforms type="simple">
<transform from="\u{30c}a" to="ǎ" /> <!-- ̌a → ǎ -->
<transform from="\u{30c}A" to="Ǎ" /> <!-- ̌A → Ǎ -->
<transform from="\u{30a}a" to="å" /> <!-- ̊a → å -->
<transform from="\u{30a}A" to="Å" /> <!-- ̊A → Å -->
</transforms>
...
</keyboard>
For example:
<transform from="\u037A\u037A" to="\u037A" error="fail" />
This indicates that it is an error to type two iota subscripts immediately after each other.
In terms of how these different attributes work in processing a sequences of transforms, consider the transform:
<transform before="X" from="Y" after="Y" to="B"/>
This would transform the string:
XYZ → XBZ
If we mark where the current match position is before and after the transform we see:
X | Y Z → X B | Z
And a subsequent transform could transform the Z string, looking back (using @before) to match the B.
There are other keying behaviors that are needed particularly in handling languages and scripts from various parts of the world. The behaviors intended to be covered by the transforms are:
We consider each transform type in turn and consider attributes to the <transforms> element pertinent to that type.
The reorder transform is applied after all transform except for those with type=“final”.
This transform has the job of reordering sequences of characters that have been typed, from their typed order to the desired output order. The primary concern in this transform is to sort combining marks into their correct relative order after a base, as described in this section. The reorder transforms can be quite complex, keyboard layouts will almost always import them.
The reordering algorithm consists of four parts:
The primary order of a character with the Unicode property Combining_Character_Class (ccc) of 0 may well not be 0. In addition, a character may receive a different primary order dependent on context. For example, in the Devanagari sequence ka halant ka, the first ka would have a primary order 0 while the halant ka sequence would give both halant and the second ka a primary order > 0, for example 2. Note that “base” character in this discussion is not a Unicode base character. It is instead a character with primary=0.
In order to get the characters into the correct relative order, it is necessary not only to order combining marks relative to the base character, but also to order some combining marks in a subsequence following another combining mark. For example in Devanagari, a nukta may follow consonant character, but it may also follow a conjunct consisting of a consonant, halant, consonant. Notice that the second consonant is not, in this model, the start of a new run because some characters may need to be reordered to before the first base, for example repha. The repha would get primary < 0, and be sorted before the character with order = 0, which is, in the case of Devanagari, the initial consonant of the orthographic syllable.
The reorder transform consists of a single element type: <reorder> encapsulated in a <reorders> element. Each is a rule that matches against a string of characters with the action of setting the various ordering attributes (primary, tertiary, tertiary_base, prebase) for the matched characters in the string.
from This attribute follows the transform/@from attribute and contains a string of elements. Each element matches one character and may consist of a codepoint or a UnicodeSet (both as defined in UTS#35 section 5.3.3). This attribute is required.
before This attribute follows the transform/@before attribute and contains the element string that must match the string immediately preceding the start of the string that the @from matches.
after This attribute follows the transform/@after attribute and contains the element string that must match the string immediately following the end of the string that the @from matches.
order This attribute gives the primary order for the elements in the matched string in the @from attribute. The value is a simple integer between -128 and +127 inclusive, or a space separated list of such integers. For a single integer, it is applied to all the elements in the matched string. Details of such list type attributes are given after all the attributes are described. If missing, the order value of all the matched characters is 0. We consider the order value for a matched character in the string.
- If the value is 0 and its tertiary value is 0, then the character is the base of a new run.
- If the value is 0 and its tertiary value is non-zero, then it is a normal character in a run, with ordering semantics as described in the @tertiary attribute.
- If the value is negative, then the character is a primary character and will reorder to be before the base of the run.
- If the value is positive, then the character is a primary character and is sorted based on the order value as the primary key following a previous base character.
A character with a zero tertiary value is a primary character and receives a sort key consisting of:
- Primary weight is the order value
- Secondary weight is the index of the character. This may be any value (character index, codepoint index) such that its value is greater than the character before it and less than the character after it.
- Tertiary weight is 0.
- Quaternary weight is the same as the secondary weight.
tertiary This attribute gives the tertiary order value to the characters matched. The value is a simple integer between -128 and +127 inclusive, or a space separated list of such integers. If missing, the value for all the characters matched is 0. We consider the tertiary value for a matched character in the string.
- If the value is 0 then the character is considered to have a primary order as specified in its order value and is a primary character.
- If the value is non zero, then the order value must be zero otherwise it is an error. The character is considered as a tertiary character for the purposes of ordering.
A tertiary character receives its primary order and index from a previous character, which it is intended to sort closely after. The sort key for a tertiary character consists of:
- Primary weight is the primary weight of the primary character
- Secondary weight is the index of the primary character, not the tertiary character
- Tertiary weight is the tertiary value for the character.
- Quaternary weight is the index of the tertiary character.
tertiary_base This attribute is a space separated list of "true" or "false" values corresponding to each character matched. It is illegal for a tertiary character to have a true tertiary_base value. For a primary character it marks that this character may have tertiary characters moved after it. When calculating the secondary weight for a tertiary character, the most recently encountered primary character with a true tertiary_base attribute is used. Primary characters with an @order value of 0 automatically are treated as having tertiary_base true regardless of what is specified for them.
prebase This attribute gives the prebase attribute for each character matched. The value may be "true" or "false" or a space separated list of such values. If missing the value for all the characters matched is false. It is illegal for a tertiary character to have a true prebase value.
If a primary character has a true prebase value then the character is marked as being typed before the base character of a run, even though it is intended to be stored after it. The primary order gives the intended position in the order after the base character, that the prebase character will end up. Thus @primary may not be 0. These characters are part of the run prefix. If such characters are typed then, in order to give the run a base character after which characters can be sorted, an appropriate base character, such as a dotted circle, is inserted into the output run, until a real base character has been typed. A value of "false" indicates that the character is not a prebase.
There is no @error attribute.
For @from attributes with a match string length greater than 1, the sort key information (@order, @tertiary, @tertiary_base, @prebase) may consist of a space separated list of values, one for each element matched. The last value is repeated to fill out any missing values. Such a list may not contain more values than there are elements in the @from attribute:
if len(@from) < len(@list) then error
else while len(@from) > len(@list)
append lastitem(@list) to @list
endwhile endif
For example, consider the word Northern Thai (nod-Lana) word: ᨡ᩠ᩅᩫ᩶ 'roasted'. This is ideally encoded as the following:
| name | ka | asat | wa | o | t2 |
|---|---|---|---|---|---|
| code | 1A21 | 1A60 | 1A45 | 1A6B | 1A76 |
| ccc | 0 | 9 | 0 | 0 | 230 |
(That sequence is already in NFC format.)
Some users may type the upper component of the vowel first, and the tone before or after the lower component. Thus someone might type it as:
| name | ka | o | t2 | asat | wa |
|---|---|---|---|---|---|
| code | 1A21 | 1A6B | 1A76 | 1A60 | 1A45 |
| ccc | 0 | 0 | 230 | 9 | 0 |
The Unicode NFC format of that typed value reorders to:
| name | ka | o | asat | t2 | wa |
|---|---|---|---|---|---|
| code | 1A21 | 1A6B | 1A60 | 1A76 | 1A45 |
| ccc | 0 | 0 | 9 | 230 | 0 |
Finally, the user might also type in the sequence with the tone after the lower component.
| name | ka | o | asat | wa | t2 |
|---|---|---|---|---|---|
| code | 1A21 | 1A6B | 1A60 | 1A45 | 1A76 |
| ccc | 0 | 0 | 9 | 0 | 230 |
(That sequence is already in NFC format.)
We want all of these sequences to end up ordered as the first. To do this, we use the following rules:
<reorder from="\u1A60" order="127"/> <!-- max possible order --> <reorder from="\u1A6B" order="42"/> <reorder from="[\u1A75-\u1A7C]" order="55"/>
<reorder before="\u1A6B" from="\u1A60\u1A45" order="10"/>
<reorder before="\u1A6B[\u1A75-\u1A7C]" from="\u1A60\u1A45" order="10"/>
<reorder before="\u1A6B" from="\u1A60[\u1A75-\u1A7C]\u1A45" order="10 55 10"/>
The first reorder is the default ordering for the asat which allows for it to be placed anywhere in a sequence, but moves any non-consonants that may immediately follow it, back before it in the sequence. The next two rules give the orders for the top vowel component and tone marks respectively. The next three rules give the asat and wa characters a primary order that places them before the o. Notice particularly the final reorder rule where the asat+wa is split by the tone mark. This rule is necessary in case someone types into the middle of previously normalized text.
<reorder> elements are priority ordered based first on the length of string their @from attribute matches and then the sum of the lengths of the strings their @before and @after attributes match.
If a layout has two <transforms> elements of type reorder, e.g. from importing one and specifying the second, then <transform> elements are merged. The @from string in a <reorder> element describes a set of strings that it matches. This also holds for the @before and @after attributes. The intersection of two <reorder> elements consists of the intersections of their @from, @before and @after string sets. It is illegal for the intersection between any two <reorder> elements in the same <transforms> element to be non empty, although implementors are encouraged to have pity on layout authors when reporting such errors, since they can be hard to track down.
If two <reorder> elements in two different <transforms> elements have a non empty intersection, then they are split and merged. They are split such that where there were two <reorder> elements, there are, in effect (but not actuality), three elements consisting of:
When merging the other attributes, the second rule is taken to have priority (occurring later in the layout description file). Where the second rule does not define the value for a character but the first does, it is taken from the first rule, otherwise it is taken from the second rule.
Notice that it is possible for two rules to match the same string, but for them not to merge because the distribution of the string across @before, @from, and @after is different. For example:
<reorder before="ab" from="cd" after="e"/>
would not merge with:
<reorder before="a" from="bcd" after="e"/>
When two <reorders> elements merge as the result of an import, the resulting reorder elements are sorted into priority order for matching.
Consider this fragment from a shared reordering for the Myanmar script:
<!-- medial-r --> <reorder from="\u103C" order="20"/> <!-- [medial-wa or shan-medial-wa] --> <reorder from="[\u103D\u1082]" order="25"/> <!-- [medial-ha or shan-medial-wa]+asat = Mon asat -->
<reorder from="[\u103E\u1082]\u103A" order="27"/> <!-- [medial-ha or mon-medial-wa] -->
<reorder from="[\u103E\u1060]" order="27"/> <!-- [e-vowel or shan-e-vowel] -->
<reorder from="[\u1031\u1084]" order="30"/>
<reorder from="[\u102D\u102E\u1033-\u1035\u1071-\u1074\u1085\u109D\uA9E5]" order="35"/>
A particular Myanmar keyboard layout can have this reorders element:
<reorders type="reorder">
<!-- Kinzi --> <reorder from="\u1004\u103A\u1039" order="-1"/> <!-- e-vowel --> <reorder from="\u1031" prebase="1"/> <!-- medial-r --> <reorder from="\u103C" prebase="1"/>
</reorders>
The effect of this that the e-vowel will be identified as a prebase and will have an order of 30. Likewise a medial-r will be identified as a prebase and will have an order of 20. Notice that a shan-e-vowel will not be identified as a prebase (even if it should be!). The kinzi is described in the layout since it moves something across a run boundary. By separating such movements (prebase or moving to in front of a base) from the shared ordering rules, the shared ordering rules become a self-contained combining order description that can be used in other keyboards or even in other contexts than keyboarding.
The final transform is applied after the reorder transform. It executes in a similar way to the simple transform with the settings ignored, as if there were no settings in the <settings> element.
This is an example from Khmer where split vowels are combined after reordering.
<transforms type="final">
<transform from="\u17C1\u17B8" to="\u17BE"/>
<transform from="\u17C1\u17B6" to="\u17C4"/>
</transforms>
Another example allows a keyboard implementation to alert or stop people typing two lower vowels in a Burmese cluster:
<transform from="[\u102F\u1030\u1048\u1059][\u102F\u1030\u1048\u1059]" error="fail"/>
The backspace transform is an optional transform that is not applied on input of normal characters, but is only used to perform extra backspace modifications to previously committed text.
Keyboarding applications typically, but are not required, to work in one of two modes:
In the text entry mode, there is no need for any special description of backspace behaviour. A keyboarding application will typically keep a history of previous output states and just revert to the previous state when backspace is hit.
In text editing mode, different keyboard layouts may behave differently in the same textual context. The backspace transform allows the keyboard layout to specify the effect of pressing backspace in a particular textual context. This is done by specifying a set of backspace rules that match a string before the cursor and replace it with another string. The rules are expressed as backspace elements encapsulated in a backspaces element.
The backspace element has the same @before, @from, @after, @to, @errors of the transform element. The @to is optional with backspace.
For example, consider deleting a Devanagari ksha:
<backspaces> <backspace from="\u0915\u094D\u0936"/> </backspaces>
Here there is no @to attribute since the whole string is being deleted. This is not uncommon in the backspace transforms.
A more complex example comes from a Burmese visually ordered keyboard:
<backspaces> <!-- Kinzi -->
<backspace from="[\u1004\u101B\u105A]\u103A\u1039"/> <!-- subjoined consonant -->
<backspace from="\u1039[\u1000-\u101C\u101E\u1020\u1021\u1050\u1051\u105A-\u105D]"/>
<!-- tone mark --> <backspace from="\u102B\u103A"/>
<!-- Handle prebases --> <!-- diacritics stored before e-vowel -->
<backspace from="[\u103A-\u103F\u105E-\u1060\u1082]\u1031" to="\u1031"/> <!-- diacritics stored before medial r -->
<backspace from="[\u103A-\u103B\u105E-\u105F]\u103C" to="\u103C"/>
<!-- subjoined consonant before e-vowel --> <backspace from="\u1039[\u1000-\u101C\u101E\u1020\u1021]\u1031" to="\u1031"/>
<!-- base consonant before e-vowel --> <backspace from="[\u1000-\u102A\u103F-\u1049\u104E]\u1031" to="\uFDDF\u1031"/>
<!-- subjoined consonant before medial r --> <backspace from="\u1039[\u1000-\u101C\u101E\u1020\u1021]\u103C" to="\u103C"/>
<!-- base consonant before medial r --> <backspace from="[\u1000-\u102A\u103F-\u1049\u104E]\u103C" to="\uFDDF\u103C"/>
<!-- delete lone medial r or e-vowel --> <backspace from="\uFDDF[\u1031\u103C]"/>
</backspaces>
The above example is simplified, and doesn't fully handle the interaction between medial-r and e-vowel.
The character \uFDDF does not represent a literal character, but is instead a special placeholder, a "filler string". When a keyboard implementation handles a user pressing a key that inserts a prebase character, it also has to insert a special filler string before the prebase to ensure that the prebase character does not combine with the previous cluster. See the reorder transform for details. The precise filler string is implementation dependent. Rather than requiring keyboard layout designers to know what the filler string is, we reserve a special character that the keyboard layout designer may use to reference this filler string. It is up to the keyboard implementation to, in effect, replace that character with the filler string.
The first three transforms above delete various ligatures with a single keypress. The other transforms handle prebase characters. There are two in this Burmese keyboard. The transforms delete the characters preceding the prebase character up to base which gets replaced with the prebase filler string, which represents a null base. Finally the prebase filler string + prebase is deleted as a unit.
The backspace transform is much like other transforms except in its processing model. If we consider the same transform as in the simple transform example, but as a backspace:
<backspace before="X" from="Y" after="Z" to="B"/>
This would transform the string:
XYZ → XBZ
If we mark where the current match position is before and after the transform we see:
X Y | Z → X B | Z
Whereas a simple or final transform would then run other transforms in the transform list, advancing the processing position until it gets to the end of the string, the backspace transform only matches a single backspace rule and then finishes.
There is a separate XML structure for platform-specific configuration elements. The most notable component is a mapping between the hardware key codes to the ISO layout positions for that platform.
This is the top level element. This element contains a set of elements defined below. A document shall only contain a single instance of this element.
Syntax
<platform>
{platform-specific elements}
</platform>
This element must have a platform element as its parent. This element contains a set of map elements defined below. A document shall only contain a single instance of this element.
Syntax
<platform>
<hardwareMap>
{a set of map elements}
</hardwareMap>
</platform>
This element must have a hardwareMap element as its parent. This element maps between a hardware keycode and the corresponding ISO layout position of the key.
Syntax
<map keycode="{hardware keycode}" iso="{ISO layout position}"/>
Examples
<platform>
<hardwareMap>
<map keycode="2" iso="E01" />
<map keycode="3" iso="E02" />
<map keycode="4" iso="E03" />
<map keycode="5" iso="E04" />
<map keycode="6" iso="E05" />
<map keycode="7" iso="E06" />
<map keycode="41" iso="E00" />
</hardwareMap>
</platform>
Beyond what the DTD imposes, certain other restrictions on the data are imposed on the data.
Notation |
Notes |
Lower case character (eg. x ) |
Interpreted as any combination of modifiers. |
Upper-case character (eg. Y ) |
Interpreted as a single modifier key (which may or may not have a
L and R variant) |
Y? ⇔ Y ∨ ∅ Y ⇔ LY ∨ RY ∨ LYRY |
Eg. Opt? ⇔ ROpt ∨ LOpt ∨ ROptLOpt ∨ ∅ |
Axiom |
Example |
xY ∨ x ⇒ xY? |
OptCtrlShift OptCtrl → OptCtrlShift? |
xRY ∨ xY? ⇒ xY? xLY ∨ xY? ⇒ xY? |
OptCtrlRShift OptCtrlShift? → OptCtrlShift? |
xRY? ∨ xY ⇒ xY? xLY? ∨ xY ⇒ xY? |
OptCtrlRShift? OptCtrlShift → OptCtrlShift? |
xRY? ∨ xY? ⇒ xY? xLY? ∨ xY? ⇒ xY? |
OptCtrlRShift? OptCtrlShift? → OptCtrlShift? |
xRY ∨ xY ⇒ xY xLY ∨ xY ⇒ xY |
OptCtrlRShift OptCtrlShift → OptCtrlShift? |
LY?RY? |
OptRCtrl?LCtrl? → OptCtrl? |
xLY? ⋁ xLY ⇒ xLY? |
|
xY? ⋁ xY ⇒ xY? |
|
xY? ⋁ x ⇒ xY? |
|
xLY? ⋁ x ⇒ xLY? |
|
xLY ⋁ x ⇒ xLY? |
Here is a list of the data sources used to generate the initial key map layouts:
Platform |
Source |
Notes |
Android |
Android 4.0 - Ice Cream Sandwich |
Parsed layout files located in packages/inputmethods/LatinIME/java/res |
ChromeOS |
The ChromeOS represents a very small subset of the keyboards available from XKB. |
|
Mac OSX |
Ukelele bundled System Keyboards (http://scripts.sil.org/cms/scripts/page.php?site_id=nrsi&id=ukelele) |
These layouts date from Mac OSX 10.4 and are therefore a bit outdated |
Windows |
Generated .klc files from the Microsoft Keyboard Layout Creator (http://msdn.microsoft.com/en-us/goglobal/bb964665) |
For interactive layouts, see also http://msdn.microsoft.com/en-us/goglobal/bb964651 |
There is a set of subtags that help identify the keyboards. Each of these are used after the "t-k0" subtags to help identify the keyboards. The first tag appended is a mandatory platform tag followed by zero or more tags that help differentiate the keyboard from others with the same locale code.
The following are the design principles for the ids.
Platform |
No modifier combination match is available |
No map match is available for key position |
Transform fails (ie. if ^d is pressed when that transform does not exist) |
ChromeOS |
Fall back to base |
Fall back to character in a keyMap with same "level" of modifier
combination. If this character does not exist, fall back to (n-1)
level. (This is handled data-generation side). |
No output at all |
Mac OSX |
Fall back to base (unless combination is some sort of keyboard shortcut, eg. cmd-c) |
No output |
Both keys are output separately |
Windows |
No output |
No output |
Both keys are output separately |
Copyright © 2001–2018 Unicode, Inc. All Rights Reserved. The Unicode Consortium makes no expressed or implied warranty of any kind, and assumes no liability for errors or omissions. No liability is assumed for incidental and consequential damages in connection with or arising out of the use of the information or programs contained or accompanying this technical report. The Unicode Terms of Use apply.
Unicode and the Unicode logo are trademarks of Unicode, Inc., and are registered in some jurisdictions.